Dual-Space NeRF: Learning Animatable Avatars and Scene Lighting in Separate Spaces
Abstract
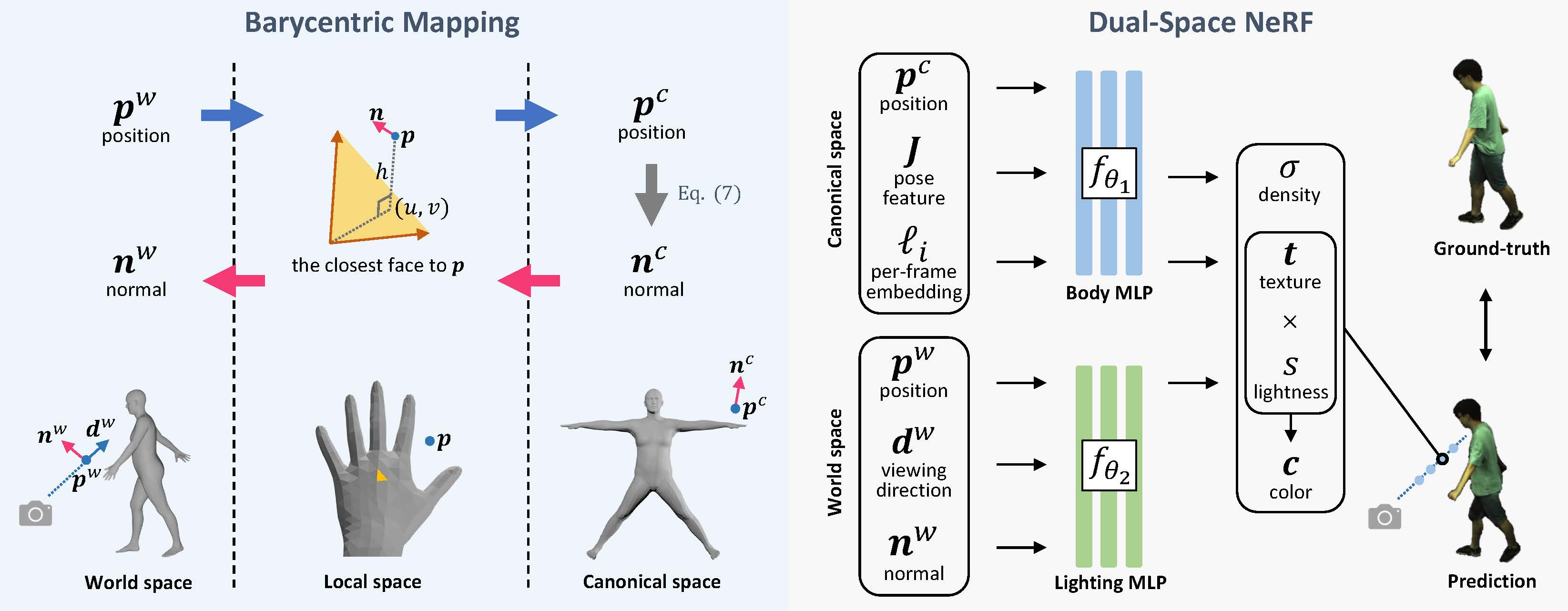
Modeling the human body in a canonical space is a common practice for capturing and animation. But when involving the neural radiance field (NeRF), learning a static NeRF in the canonical space is not enough because the lighting of the body changes when the person moves even though the scene lighting is constant. Previous methods alleviate the inconsistency of lighting by learning a per-frame embedding, but this operation does not generalize to unseen poses. Given that the lighting condition is static in the world space while the human body is consistent in the canonical space, we propose a dual-space NeRF that models the scene lighting and the human body with two MLPs in two separate spaces. To bridge these two spaces, previous methods mostly rely on the linear blend skinning (LBS) algorithm. However, the blending weights for LBS of a dynamic neural field are intractable and thus are usually memorized with another MLP, which does not generalize to novel poses. Although it is possible to borrow the blending weights of a parametric mesh such as SMPL, the interpolation operation introduces more artifacts. In this paper, we propose to use the barycentric mapping, which can directly generalize to unseen poses and surprisingly achieves superior results than LBS with neural blending weights. Quantitative and qualitative results on the Human3.6M and the ZJU-MoCap datasets show the effectiveness of our method.