Flow4R: Unifying 4D Reconstruction and Tracking with Scene Flow

Abstract
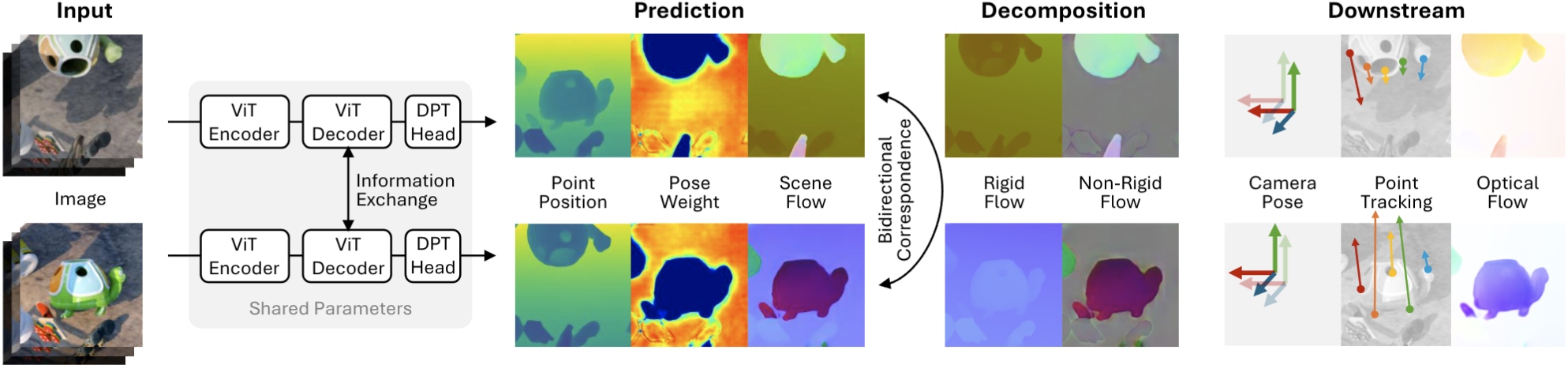
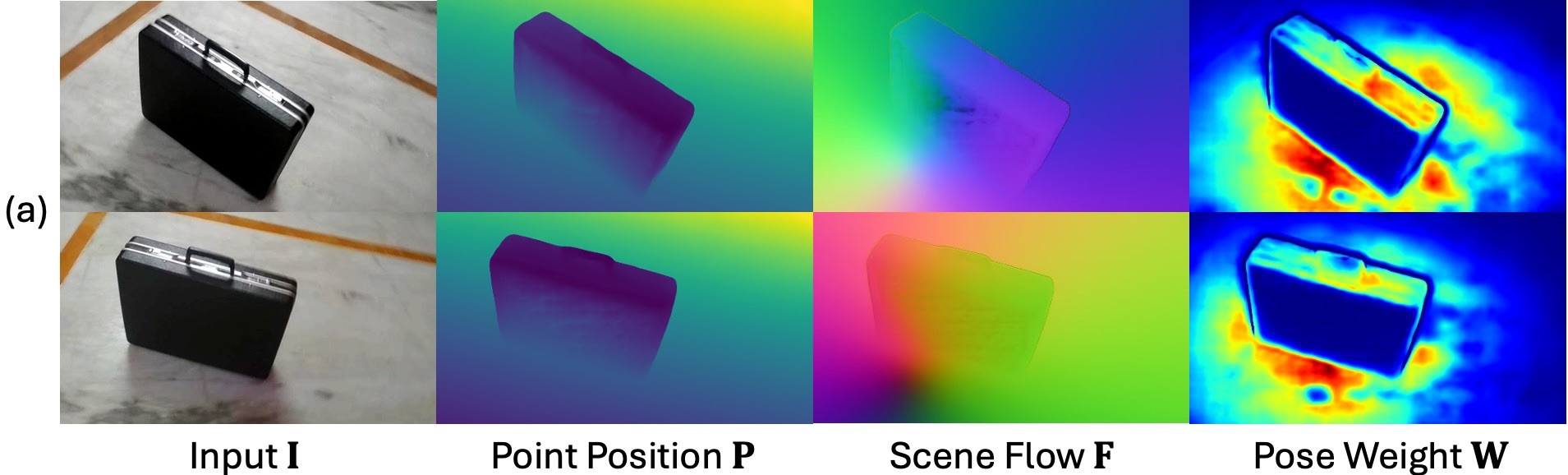
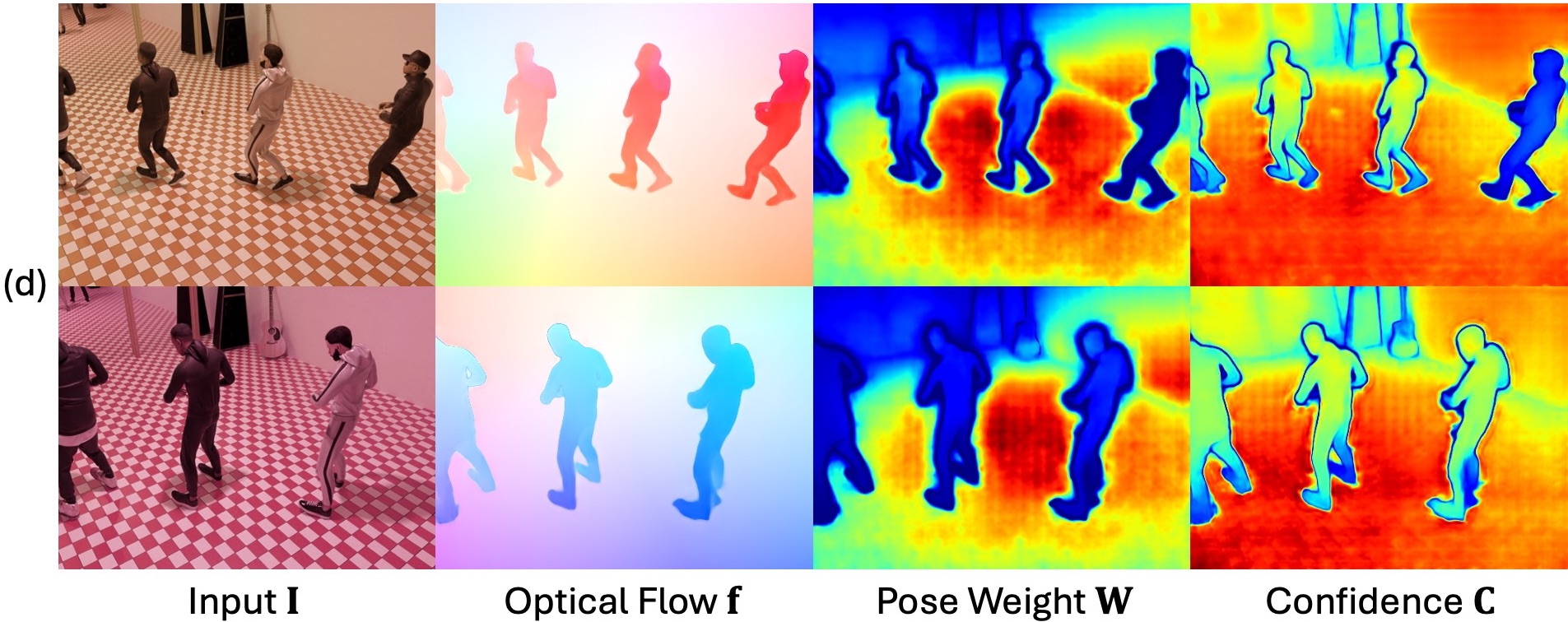
Reconstructing and tracking dynamic 3D scenes remains a fundamental challenge in computer vision. Existing approaches often decouple geometry from motion: multi-view reconstruction methods assume static scenes, while dynamic tracking frameworks rely on explicit camera pose estimation or separate motion models. We propose Flow4R, a unified framework that treats camera-space scene flow as the central representation linking 3D structure, object motion, and camera motion. Flow4R predicts a minimal per-pixel property set—3D point position, scene flow, pose weight, and confidence—from two-view inputs using a Vision Transformer. This flow-centric formulation allows local geometry and bidirectional motion to be inferred symmetrically with a shared decoder in a single forward pass, without requiring explicit pose regressors or bundle adjustment. Trained jointly on static and dynamic datasets, Flow4R achieves state-of-the-art performance on 4D reconstruction and tracking tasks, demonstrating the effectiveness of the flow-central representation for spatiotemporal scene understanding.
Pipeline
Evaluation
World Coordinate 3D Point Tracking
| Method | All Points | Dynamic Points | # param. (B) |
|||||
|---|---|---|---|---|---|---|---|---|
| ADT | DR | PO | PS | ADT | DR | PO | ||
| MonST3R | 74.4 | 58.1 | 33.5 | 51.3 | 67.9 | 51.9 | 39.4 | 0.7 |
| SpaTracker | 45.7 | 54.9 | 38.5 | 62.6 | 67.7 | 58.7 | 51.2 | 0.2 |
| POMATO | 57.2 | 68.4 | 49.7 | 64.9 | 78.1 | 62.7 | 58.1 | 0.7 |
| St4RTrack | 76.0 | 73.7 | 68.0 | 69.7 | 75.3 | 68.1 | 68.7 | 0.7 |
| Flow4R | 78.6 | 78.5 | 71.1 | 64.3 | 70.9 | 77.2 | 72.9 | 0.4 |
World Coordinate 3D Reconstruction
| Category | Method | Point Odyssey | TUM-Dynamics | ||
|---|---|---|---|---|---|
| APD↑ | EPE↓ | APD↑ | EPE↓ | ||
| w/ Global Align. | DUSt3R+GA | 43.90 | 0.609 | 70.49 | 0.315 |
| MASt3R+GA | 60.44 | 0.403 | 68.38 | 0.519 | |
| MonST3R+GA | 72.31 | 0.263 | 63.87 | 0.343 | |
| Feedforward | DUSt3R | 45.79 | 0.639 | 72.26 | 0.289 |
| MASt3R | 56.90 | 0.464 | 66.22 | 0.551 | |
| MonST3R | 68.25 | 0.304 | 61.38 | 0.365 | |
| POMATO | 66.50 | 0.385 | 49.80 | 0.509 | |
| St4RTrack | 78.73 | 0.205 | 83.42 | 0.185 | |
| Flow4R | 81.00 | 0.182 | 79.87 | 0.202 | |
Visualization
2D Visualization


3D Visualization

Related Work
Our work is closely related to
- DUSt3R: Geometric 3D Vision Made Easy
- MonST3R: A Simple Approach for Estimating Geometry in the Presence of Motion
- ZeroMSF: Zero-shot Monocular Scene Flow Estimation in the Wild
- Dynamic Point Maps: A Versatile Representation for Dynamic 3D Reconstruction
- St4RTrack: Simultaneous 4D Reconstruction and Tracking in the World
- POMATO: Marrying Pointmap Matching with Temporal Motions for Dynamic 3D Reconstruction
- D²USt3R: Enhancing 3D Reconstruction with 4D Pointmaps for Dynamic Scenes
Moving away from dedicated decoders for specific coordinate systems or timestamps, Flow4R adopts a symmetrical architecture that predicts local geometry and relative motion using a shared decoder and head.
Acknowledgments
This work was supported by the ERC Advanced Grant “SIMULACRON” (agreement #884679), the GNI Project “AI4Twinning”, the DFG project CR 250/26-1 “4DYoutube”, the Leibniz Supercomputing Centre (LRZ), and the UKRI AIRR programme. We would like to thank Weirong Chen, Dominik Muhle, and Linus Härenstam-Nielsen for valuable discussions throughout the project.